Paper: Robustness May Be at Odds with Accuracy
Authors: Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, Aleksander Mądry
Venue: ICLR 2019
Introduction
Deep learning models have achieved outstanding performance on a variety of benchmarks in computer vision, speech recognition, and other domains. In practice, however, these models are extremely brittle: small, human-imperceptible changes (adversarial perturbations) can cause a model to make highly confident yet incorrect predictions.
To defend against such adversarial examples, defense techniques such as adversarial training have been actively studied. However, making models robust comes with several “costs.” Not only does training require substantially more computation and a much larger volume of training data, but it has been consistently observed that the standard accuracy of the model decreases noticeably.
Is this trade-off between robustness and accuracy merely a limitation of current training methodologies or optimization techniques? This paper demonstrates – both mathematically and empirically, using a simple data distribution – that a fundamental trade-off may exist between the two objectives of adversarial robustness and standard generalization.
Two Objectives in Classification
The standard classification setting in traditional machine learning and the adversarial setting fundamentally differ in the objective function being optimized.
- Standard Accuracy: To maximize the average prediction accuracy on new samples, the population risk is minimized as follows.
- Adversarial Robustness: To maintain the correct prediction even when an adversary injects noise $\delta$ of bounded magnitude into the input, the worst-case loss is minimized. Constraints based on the $l_{\infty}$ norm are most commonly used as a benchmark.
Adversarial Training: Limits as Data Augmentation
In machine learning practice, adversarial training is often regarded as the most powerful form of data augmentation. The reason is that it trains the model on data perturbed by the worst-case noise, the kind that maximally confuses the model.
Indeed, the experiments in the paper show that in the low-data regime, where training data is very scarce, adversarial training acts as a regularizer, helps generalization, and can even improve standard accuracy (this is particularly pronounced on MNIST).
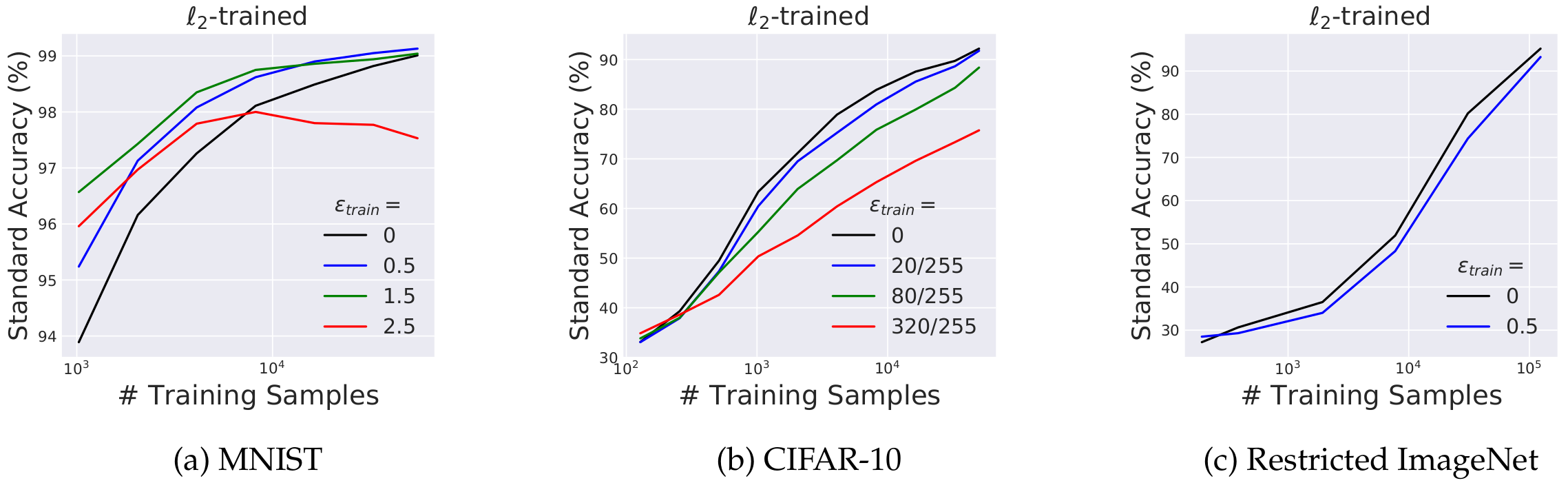
However, as the amount of training data increases, this positive effect gradually disappears. With more data, the standard-trained model converges to nearly perfect accuracy, while the adversarially trained robust model is eventually overtaken, exhibiting a clear trade-off where its standard accuracy drops below that of the standard model. On more complex datasets such as CIFAR-10 or ImageNet, where invariance to specific constraints does not contribute meaningfully to standard accuracy, this phenomenon emerges even sooner.
Trade-off Between Accuracy and Robustness: Mathematical Derivation
To prove why this trade-off is “inevitable,” the authors mathematically construct a simple toy dataset $\mathcal{D}$ for binary classification.
1. Robust Feature ($x_1$) A single feature that is strongly correlated with the label $y$ (e.g., $p=0.95$) but not perfectly. A small-magnitude attack cannot flip the sign of this feature.
2. Non-robust Features ($x_2, \dots, x_{d+1}$) Many features, each only weakly correlated with the label individually. Each feature follows a normal distribution $\mathcal{N}(\eta y, 1)$, where $\eta$ is a very small value.
Greedy Learning of the Standard Classifier and the Formation of a Meta-feature
The sole objective of a standard model is to maximize accuracy. Thus, it is not satisfied with the robust feature $x_1$ alone, which only partially predicts the label, and instead aggregates the many non-robust features that each carry only a tiny amount of information, averaging them. Statistically, summing these weak signals together produces a “meta-feature” with strong predictive confidence.
When each feature follows $x_i \sim \mathcal{N}(\eta y, 1)$, their average $z$ has the following distribution.
\[z = \frac{1}{d}\sum_{i=2}^{d+1} x_i \sim \mathcal{N}\left(\eta y, \frac{1}{d}\right)\]As the number of features $d$ grows, the variance converges to $0$, so the model becomes nearly certain of the correct label even from very weak signals, thereby achieving near-perfect standard accuracy.
Adversarial Attack and the Collapse of Accuracy
This “meta-feature,” however, has a fatal weakness. In an adversarial setting, when the attacker injects a small amount of noise into each feature in the direction opposite to the label, the distribution of the meta-feature is completely flipped.
\[z_{adv} \sim \mathcal{N}\left(-\eta y, \frac{1}{d}\right)\]As a result, the model selects the opposite of the correct label with very high confidence.
Consequently, the standard classifier – which achieved high accuracy by relying on non-robust features – has its accuracy plummet to under 1% under adversarial attack. The paper shows mathematically that, after training to minimize the adversarial loss, the model abandons its weighting on non-robust features and relies solely on the robust feature $x_1$. In other words, there is a structural limitation that requires sacrificing some accuracy in exchange for robustness.
A Fundamental Limit That Cannot Be Resolved Even with Infinite Data
It is often expected that “if we are given infinite training data, the model will become perfect, and the robustness problem will resolve itself naturally.” However, in this setting, the trade-off does not vanish even with infinite data. Even the Bayes-optimal classifier, which knows everything about the distribution, must inevitably rely on non-robust features in order to maximize standard accuracy. This implies that this trade-off is not a matter of insufficient data or limitations of optimization, but rather a fundamental dilemma inherent to the data distribution itself.
Empirical Verification and the Origin of Transferability
These mathematical phenomena are also clearly visible in experiments using the binary MNIST dataset. As shown in the figure below, the way the model assigns weights differs starkly depending on the correlation between pixels (features) and the label.
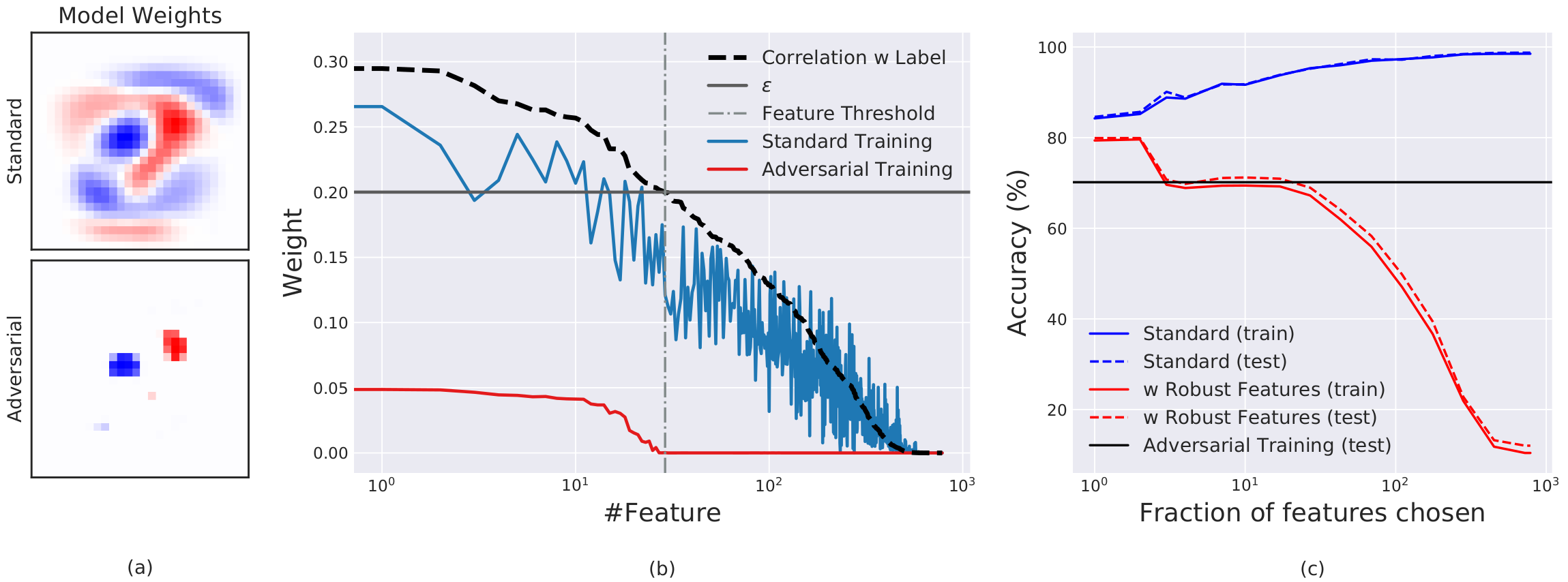
- Weight distribution of the standard model: As shown by the blue curve, the standard model assigns weights even to pixels with virtually no correlation (such as background noise). This is the result of a greedy optimization that exploits even fragile features if they offer any marginal accuracy improvement.
- Weight distribution of the robust model: As shown by the red curve, the robust model assigns weights only to key pixels whose correlation exceeds a certain threshold, in order to remain reliable against the adversary’s perturbation budget.
Why does Transferability occur? This analysis provides a strong clue about a long-standing open problem in deep learning: the transferability of adversarial examples (the phenomenon where an example that fools one model also fools another). Standard models trained on the same distribution end up, regardless of architecture, relying on the same non-robust features. Thus, an adversarial example that corrupts these weak features inevitably transfers to other independently trained classifiers.
An Alternative Approach: Achieving Robustness without Adversarial Training
Adversarial training is computationally very expensive. To overcome this limitation, the authors performed an experiment in which the model was restricted to use only highly correlated robust features during training, while training proceeded in the standard fashion. As shown in the figure above, simply excluding fragile features from learning achieved a level of defense comparable to that of full-fledged adversarial training. This suggests that designing robust models is possible through proper feature selection alone.
Unexpected Benefits of Robust Models
Although the price – a drop in accuracy – is painful, in exchange for blocking non-robust shortcuts, the robust model gains highly intuitive, human-like capabilities.

1. Models Aligned with Human Perception (Human-aligned Gradients)
Visualizing the gradient of the model’s loss function with respect to the input clearly reveals this difference. In the past, extracting such meaningful visualizations from standard networks required various complex auxiliary techniques.
In contrast, an adversarially trained model produces gradients that are perfectly aligned with perceptually meaningful features such as the contours of animals or the edges of objects, even by default. This is because the human visual prior – “humans are insensitive to small pixel-level changes” – has been mathematically encoded through the adversarial threat model.

2. Capturing Meaningful Features and the Connection to Generative Models
This property of robust models becomes even more striking when adversarial attacks are performed against them. As shown in the figure above, optimization (PGD) was carried out with a large adversarial budget ($\epsilon$) in order to fool the model.
The adversarial examples produced by the standard model look like nothing more than meaningless flickering noise. Surprisingly, however, the adversarial examples produced by the robust model visually exhibit the actual characteristic features of the target class (e.g., a dog’s fur, a bird’s beak). This suggests that the defense technique is not simply gradient obfuscation, but rather that the model has fundamentally learned the true feature distribution of the data.

Furthermore, when one performs linear interpolation between an original image and the adversarial example produced by the robust model, the result is a very natural morphing from one class into another, as illustrated above. This is a property traditionally observed only in generative models such as GANs and VAEs, hinting at a deep mathematical connection between the optimization problem of classifiers and that of generative models.
Conclusion and Future Directions
This paper shows that adversarial robustness and standard generalization (accuracy) can be fundamentally at odds, not merely as a limitation of training techniques, but as a structural property of the data itself.
Interestingly, on certain image classification benchmarks, humans are often observed to be less accurate than state-of-the-art deep learning models. The reasoning of this paper offers an explanation. Models, in order to gain even the slightest performance edge, exploit minute and fragile non-robust features that only machines can perceive. Humans, by contrast, have evolved to be invariant to such noise and rely solely on robust features; as a result, their measured accuracy on simple benchmarks may fall below that of models.
In the end, the noticeable drop in accuracy observed during adversarial training is not a flaw of the defense technique. Rather, it offers an important insight: it is a reasonable and inevitable cost that the model must pay in order to abandon meaningless statistical shortcuts and evolve toward a more interpretable, more human-like way of perceiving data.