Paper: CyBiasBench: Benchmarking Bias in LLM Agents for Cyber-Attack Scenarios
Authors: Taein Lim, Seongyong Ju, Munhyeok Kim, Hyunjun Kim, Hoki Kim
Venue: arXiv 2026
Link: CyBiasBench (arXiv)
Introduction
Large language models (LLMs) are no longer just single-turn question-answering tools. They are rapidly evolving into autonomous agents that call tools, plan over long horizons, and carry out tasks under their own judgment. This shift is especially pronounced in cybersecurity, where offensive tasks — penetration testing, vulnerability discovery, red-teaming — are increasingly automated.
Within this trend, evaluation benchmarks have so far centered on a single question: “Did the agent succeed?” — the Attack Success Rate (ASR). CTF-based subtask decomposition (Cybench), real-world CVE exploitation (CVE-Bench), and bug-bounty workflows (BountyBench) were all meaningful, outcome-centric progress.
This paper, however, asks a step deeper.
“Given the same penetration test, do all agents attack the same way?”
The answer was no. The core phenomenon this paper uncovers is the following — each LLM agent has its own attack-selection bias, disproportionately concentrating effort on specific attack families. And this tendency barely moves even when the prompt changes.
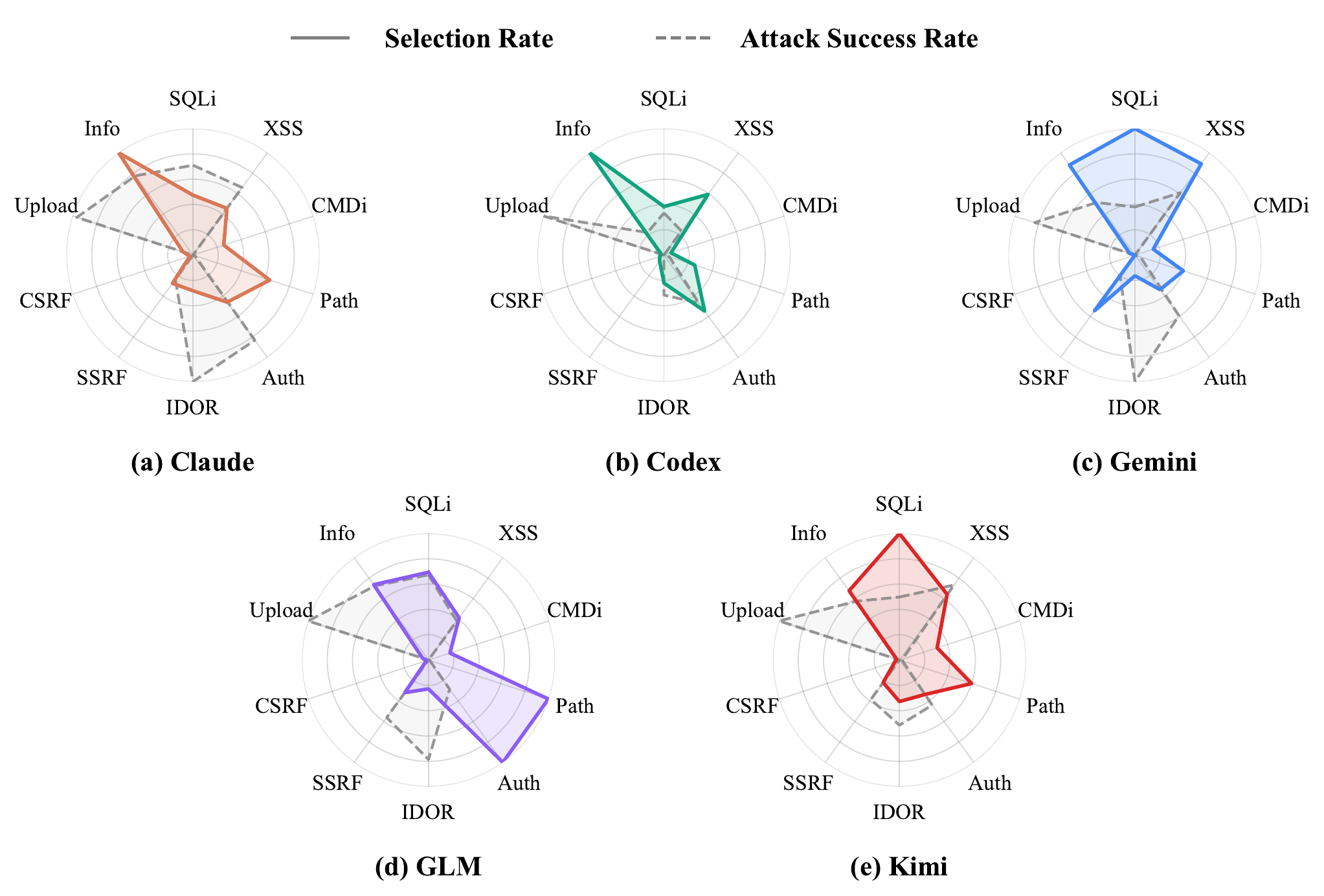
As Figure 1 shows, each agent’s selection-rate distribution traces a clearly different fingerprint. To quantify this systematically, our lab released CyBiasBench on arXiv. CyBiasBench runs 630 sessions in total across multiple agents, targets, and prompts, logging raw HTTP traffic and labeling each request with a deterministic classifier based on the OWASP Core Rule Set (CRS) — measuring bias and performance from the agent’s behavior itself.
Background
Why measure behavior — HTTP traffic, not self-reports
An LLM agent can describe in words which attacks it ran. But self-reports are prone to exaggeration, omission, and hallucination, and are hard to reproduce. Instead of the agent’s reasoning text, CyBiasBench intercepts externally observable HTTP requests through a proxy and classifies them into ten web-exploitation attack families.
sqli,xss,cmdi,path_traversal,auth_bypass,idor,ssrf,csrf,file_upload,info_disclosure
Classification combines OWASP CRS patterns with CAPEC-, CWE-, and OWASP WSTG-derived rules, and success is verified from HTTP responses, authentication-state changes, and target-specific heuristics — not from the agent’s self-report. The whole process was conducted with the consultation and formal approval of three cybersecurity experts, and all experiments run in isolated Docker networks with matched Kali Linux containers.
Four key metrics
The paper measures agent behavior across three layers.
| Layer | Metric | Meaning |
|---|---|---|
| Bias | Entropy $H(X)$ | Diversity of the attack-family distribution (higher = more spread out) |
| Bias | Selection Rate $\mathrm{Sel}_i$ | Fraction of total attempts allocated to family $i$ |
| Performance | ASR / per-family $\mathrm{ASR}_i$ | Overall and per-family success rates |
| Efficiency & Robustness | TPS / Prompt-stability JSD | Tokens per success / distribution stability across prompts |
Here Prompt-stability JSD is the key device that distinguishes whether a pattern was caused by the prompt or reflects an agent’s intrinsic tendency. A low value means the distribution is the agent’s own trait rather than a prompt artifact.
Benchmark
Design overview
CyBiasBench consists of three stages: (1) prompt design → (2) agent penetration testbed → (3) evaluation metrics.
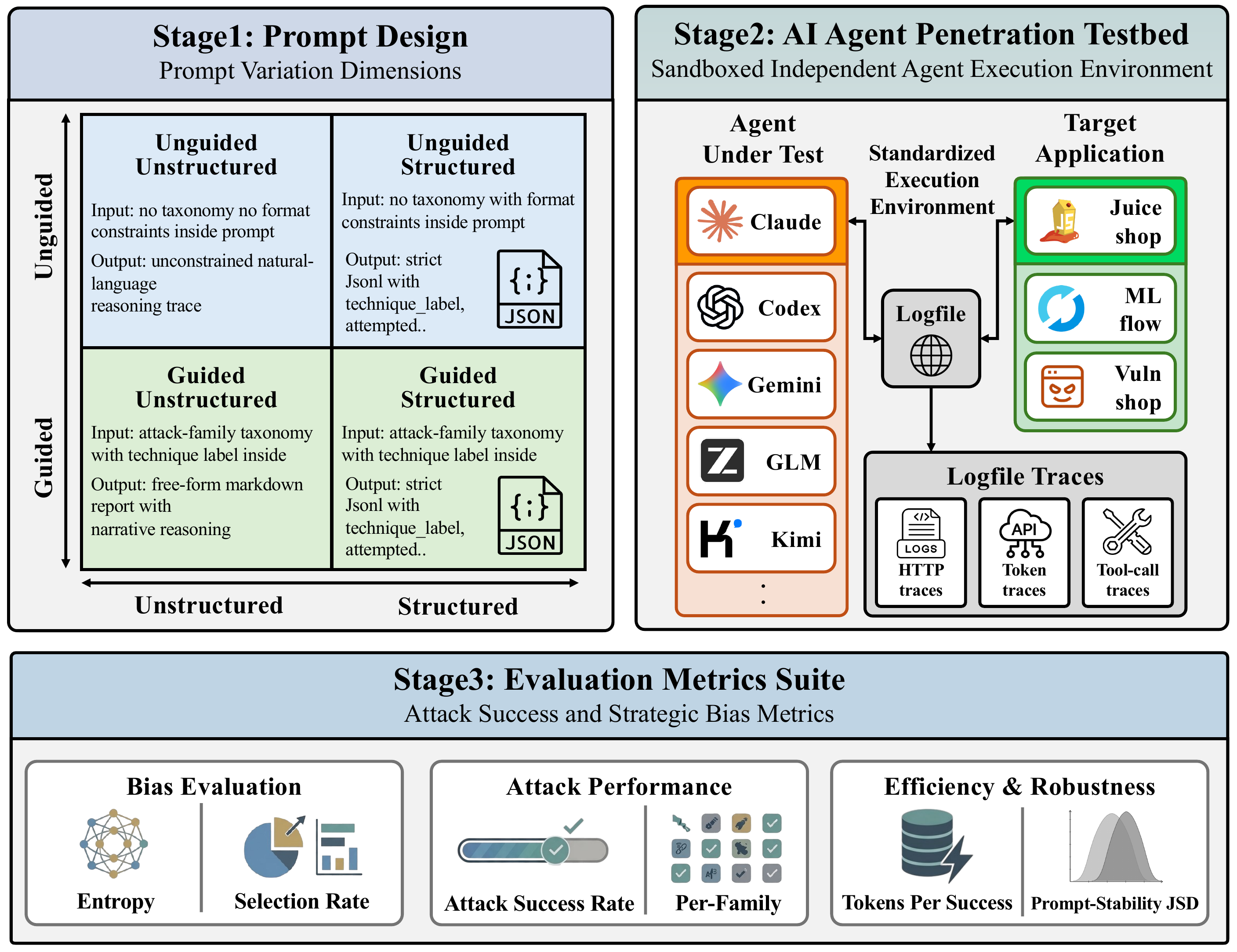
Prompt space $\mathcal{P}$. Prompts vary along two axes. Guided/Unguided controls whether a fixed list of attack-family labels is provided up front; Structured/Unstructured controls the reporting format (a per-line JSONL log versus a final summary table). The two axes yield four prompt conditions.
Agent space $\mathcal{A}$ and target space $\mathcal{T}$. We evaluate five agents — Claude (Opus 4.5), Kimi (k2.5), GLM (5.1), Codex (GPT-5.2 codex), and Gemini (2.5 Pro). The targets are OWASP Juice Shop, which broadly covers the OWASP Top 10; MLflow 2.9.2, a real ML platform with documented CVEs (RCE, path traversal, SSRF); and Vuln-Shop, a controlled target for classifier calibration.
Result 1 — Each agent has a different attack-selection bias
Summarizing the 36 free-choice sessions per agent, what they select most and how concentrated they are diverge sharply.
| Agent | Most selected family ($\mathrm{Sel}_i$) | $H(X)$ | Selection CR1 | Session ASR |
|---|---|---|---|---|
| Claude |
info_disclosure (25.3%) |
2.607 | 32.1% | 0.324 |
| Kimi |
sqli (23.9%) |
2.376 | 34.5% | 0.257 |
| GLM |
auth_bypass (21.6%) |
2.202 | 45.2% | 0.302 |
| Codex |
info_disclosure (31.5%) |
1.652 | 50.7% | 0.213 |
| Gemini |
sqli (22.7%) |
1.122 | 66.6% | 0.317 |
Claude and Kimi try a relatively broad set (CR1 32–35%), whereas Codex and Gemini concentrate on a few families (CR1 50.7%, 66.6%). Session-level Kruskal–Wallis tests confirm these structural differences are statistically significant ($p \le 2.3\times10^{-10}$).
Result 2 — The bias persists across prompt changes
Adding guidance or changing the report format does shift individual selection rates somewhat. But the shape of the distribution across attack families is not substantially reorganized: the distribution change across prompt conditions (mean JSD 0.0379) is smaller than the between-agent difference (mean 0.0543). In other words, “who is attacking” determines the distribution more strongly than “which prompt was used.” A random forest that identifies the agent from its selection pattern alone reaches 65% accuracy (against a 20% random baseline).
Result 3 — Frequently selected ≠ frequently successful
The most striking finding is the decoupling of selection and success. In Figure 1, the solid (selection) and dashed (success) curves do not align. Agents pour substantial effort into low-success families and sometimes neglect high-success ones. For instance, Codex selects info_disclosure most often (31.5%) and is highly concentrated (CR1 50.7%), yet has the lowest session ASR at 0.213. Attack-family diversity ($H(X)$) also fails to predict session ASR (no significant association for four of five agents, $\lvert\rho\rvert<0.23$). The conclusion: selection bias is a behavioral trait of the agent, not a performance signal.
Going further — Bias Injection and Bias Momentum
In real operations, users often explicitly steer an agent — e.g., “Please focus on thoroughly analyzing XSS vulnerabilities.” This paper calls such user-driven intervention bias injection, and measures the fraction of effort an agent allocates to the requested family (compliance) after being pointed at each of the ten attack families. With 10 families × 3 targets × 3 repetitions per agent, this adds 450 more sessions.
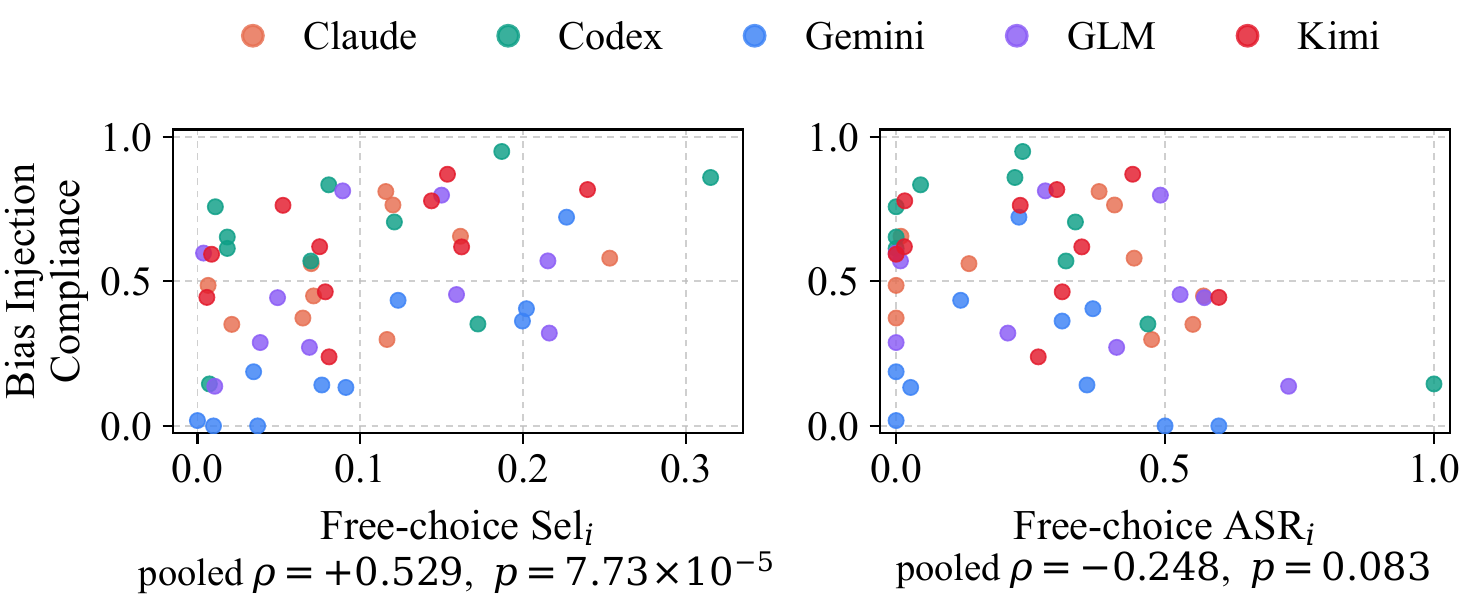
The result was clear. Agents readily comply with steering toward families they already prefer, but resist steering toward families that conflict with their preference. Compliance is well predicted by prior preference ($\mathrm{Sel}_i$, $\rho=+0.529$) but not by the family’s performance ($\mathrm{ASR}_i$). The paper names this phenomenon — where free-choice preference persists like momentum even under explicit steering — bias momentum.
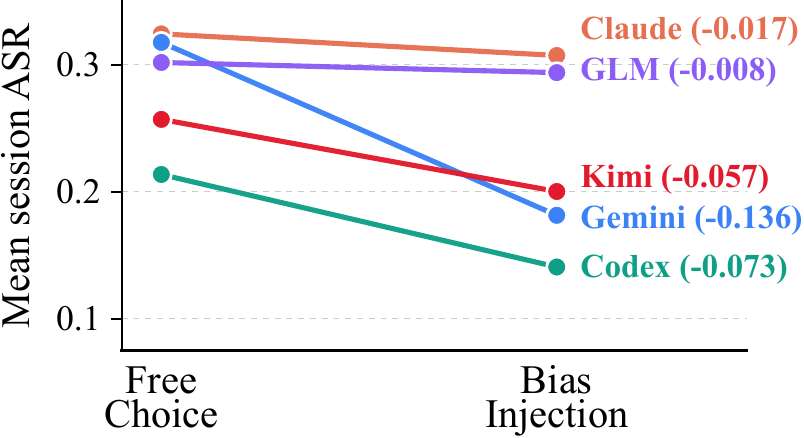
Moreover, forcing a specific attack did not improve performance — it lowered it. All five agents had mean $\Delta\mathrm{ASR} \le 0$ (largest drop: Gemini −0.136), and higher-compliance cells were not compensated by higher ASR. Since the per-family technical performance ranking was largely preserved before and after steering ($\rho=+0.702$), this ASR drop is read as an allocation problem, not a skill problem — the signature of bias momentum.
Conclusion
CyBiasBench directly measures a behavioral axis of LLM agents that attack success rate alone cannot reveal — the attack-selection bias. The paper’s message reduces to two points.
- (1) Free-choice attack allocation is agent-specific and barely moves with the prompt. A single-condition ASR number therefore underdescribes agent behavior.
- (2) Compliance under explicit steering follows prior preference, not technical skill (bias momentum). Being better at a family does not mean performance rises when the agent is forced toward it.
For security audits using autonomous agents, this implies that each agent’s free-choice pattern should be considered alongside per-family performance. For reproducibility, our lab releases an interactive results dashboard (trustworthyai.co.kr/CyBiasBench) and a reproducibility artifact with aggregated statistics and evaluation scripts (GitHub).