논문명: Towards Evaluating the Robustness of Neural Networks
저자: Nicholas Carlini, David Wagner
게재지: 2017 IEEE Symposium on Security and Privacy (SP)
서론
딥러닝 분류 모델은 높은 정확도를 보이지만, 입력에 매우 작은 섭동(perturbation)만 더해도 원하는 오분류를 유도할 수 있습니다. 이런 적대적 예제(adversarial example) 는 자율주행, 악성코드 탐지, 음성 인식처럼 보안 민감도가 높은 분야에서 모델의 실사용을 어렵게 만듭니다.
이 논문은 당시 강력한 방어로 주목받던 Defensive distillation 을 정면으로 검증합니다. 기존 보고에 따르면 distillation은 기존 공격의 성공률을 95%에서 0.5%까지 떨어뜨린다고 알려졌습니다. 그러나 저자들은 그것이 “모델이 진짜로 강건해졌기 때문”이라기보다, 기존 공격 알고리즘이 취약해서 실패한 것일 수 있다고 봅니다.
이를 검증하기 위해 저자들은 \(L_0\), \(L_2\), \(L_{\infty}\) 거리 제약 각각에 대응하는 세 가지 새로운 공격을 제안합니다. 그리고 이 공격들이 일반 모델뿐 아니라 defensively distilled 모델에서도 100% 성공률로 적대적 예제를 찾을 수 있음을 보입니다.
이 논문의 핵심 메시지는 단순합니다. 방어가 기존 공격을 막았다고 해서 강건성이 확보된 것은 아니다. 더 강한 공격, 더 안정적인 목적함수, 그리고 전이성(transferability) 기반 평가까지 함께 봐야 robust하다고 말할 수 있습니다.
사전지식
위협 모델
논문은 기본적으로 White-box attack를 가정합니다. 즉, 공격자는 모델 구조, 파라미터, gradient에 모두 접근할 수 있습니다. 저자들은 이것이 보수적이지만 현실적인 가정이라고 봅니다. 왜냐하면 black-box 환경에서도 substitute model을 학습한 뒤 공격을 전이시키는 방식이 가능하기 때문입니다.
표기
| 기호 | 의미 |
|---|---|
| \(F(x)\) | softmax를 포함한 전체 분류 모델 출력 |
| \(Z(x)\) | softmax 직전의 logit 출력 |
| \(C(x)\) | 모델이 예측한 클래스 |
| \(C^*(x)\) | 입력 \(x\)의 실제 정답 클래스 |
| \(x\) | 원본 입력 |
| \(x' = x + \delta\) | 적대적 예제 |
| \(t\) | 공격자가 원하는 target class |
| \(D(x, x')\) | 원본과 적대적 예제 사이 거리 |
Targeted 공격
이 논문은 untargeted보다 더 강한 targeted attack 을 기준으로 공격을 평가합니다. 이 방식은 적대적 공격이 단순히 오분류만 유도하는 것이 아니라, 공격자가 지정한 클래스 \(t\)로 분류하게 만듭니다.
거리 척도
논문은 기존 연구와 동일하게 세 가지 \(L_p\)를 사용합니다.
| 거리 | 의미 |
|---|---|
| \(L_0\) | 수정된 픽셀의 총 개수 |
| \(L_2\) | 원본 이미지와 수정 이미지의 유클리드 거리 |
| \(L_{\infty}\) | 수정 이후 최대 픽셀 변화량 |
저자들은 어느 거리 척도가 인간 지각과 가장 잘 맞는지 단정하지 않습니다. 위 세 가지 기준이 당시 문헌에서 가장 널리 쓰였고, distillation 논문도 이 척도들로 안전성을 주장했기 때문에 이들을 동일 기준으로 비교합니다.
Defensive distillation
Defensive distillation은 원래 모델 압축용 distillation을 방어 목적으로 바꿔 쓴 방식입니다.
- 임의의 상수 temperature \(T\)를 도입해 teacher network를 학습합니다.
이때의 softmax는 아래의 모습이며, \(T\)가 증가할수록 각 클래스 간의 확률 차이가 줄어들어 softmax 출력이 더 균등해집니다.
\[\operatorname{softmax}(x, T)_i = \frac{e^{x_i/T}}{\sum_j e^{x_j/T}}\]- 학습된 teacher network를 통해 전체 학습 데이터에 대한 soft label을 생성합니다.
- 이 soft label을 정답 레이블로 삼아, teacher network와 동일한 구조의 student network를 학습시킵니다.
- student network를 테스트할 때는 temperature를 1로 복구시킨 뒤, 일반 분류 모델처럼 사용합니다.
기존 연구들은 높은 \(T\)가 decision boundary를 부드럽게 만들어 적대적 예제에 덜 취약해진다고 주장합니다. 그러나 본 논문은 그 해석이 잘못되었음을 보입니다. 당시 Defensive distillation의 안전성은 주로 “기존 공격들이 distilled model에서 잘 동작하지 않았다”는 결과에 기반했습니다. 따라서 이 방어를 제대로 평가하려면, 먼저 당시 표준으로 쓰이던 공격들이 무엇이었고 그 공격들이 정말 모델의 robustness에 대한 신뢰할 수 있는 upper bound를 제공하는지부터 점검해야 합니다.
기존 공격 기법
논문은 바로 이 문제의식에서 기존 공격들을 정리한 뒤, 왜 해당 공격들만으로는 모델의 강건성을 평가하기 부족한지 보여 줍니다.
| 공격 기법 | 최적화 대상 | 특징 |
|---|---|---|
| L-BFGS | \(L_2\) | 초기 adversarial example 연구의 대표적 최적화 기반 공격 |
| Fast Gradient Sign (FGS/FGSM) | \(L_{\infty}\) | 모든 픽셀을 동시에 한 번 조작해 적대적 예제를 매우 빠르게 생성 |
| Iterative Gradient Sign | \(L_{\infty}\) | FGSM의 반복형. 작은 크기만큼 여러 번 이미지를 조작해 더 세밀한 공격 가능 |
| JSMA | \(L_0\) | Jacobian saliency map 기준으로 영향력이 큰 일부 픽셀만 선택하여 조작 |
| DeepFool | 주로 \(L_2\) | untargeted. 샘플의 분류 결과가 변하는 가장 가까운 결정경계까지의 거리를 바탕으로 샘플 조작 |
이 논문의 관점에서 기존 공격 기법들의 문제는 다음과 같습니다.
-
일부 공격은 빠르게 적대적 예제를 생성하도록 설계되었지만, 최소한의 적대적 섭동을 생성하지는 않기 때문에 최적성이 부족합니다.
-
일부 공격은 목적 함수나 gradient의 안정성에 민감합니다. Defensive distillation으로 학습된 모델은 테스트 시 Gradient Vanishing이 발생하기 때문에 gradient 정보를 잃습니다. 결국 공격 알고리즘은 최적화 경로 탐색에 실패하는 수치적 불안정성에 빠지게 됩니다.
저자들은 바로 이 지점에서 기존 평가 방식의 한계를 주장합니다. 강건성 평가는 결국 얼마나 강한 공격으로 모델의 취약성에 대한 upper bound를 주느냐의 문제인데, 공격 자체가 불안정하다면 “방어가 안전하다”는 결론도 신뢰하기 어렵습니다. 따라서 논문은 공격 알고리즘 자체를 더 강하고 안정적으로 다시 설계하는 방향을 제시합니다.
제안 방법
기본 최적화 관점
저자들은 적대적 예제 생성을 다음 constrained optimization으로 둡니다.
\[\min_{\delta} D(x, x+\delta) \quad \text{s.t.} \quad C(x+\delta)=t,\; x+\delta \in [0,1]^n\]하지만 모델의 분류 결과는 레이블로써 이산적이고 불연속적이기 때문에 문제의 분류 제약 조건 \(C(x+\delta)=t\) 을 직접 다루기 어렵습니다. 따라서 분류 제약을 목적함수에 녹여 아래처럼 변형합니다.
\[\min_{\delta} \|\delta\|_p + c \cdot f(x+\delta) \quad \text{s.t.} \quad x+\delta \in [0,1]^n\]여기서 추가된 \(f(x+\delta)\) 는 원래의 분류 제약을 대신하는 연속적이고 최적화 가능한 penalty term 입니다. 즉, \(x+\delta\) 가 target class \(t\) 로 분류되면 작아지거나 0 이하가 되도록 설계해, 최적화 과정이 “이미지를 원본과 가깝게 유지하는 것”과 “타깃 클래스로 오분류시키는 것”을 동시에 밀어가도록 만듭니다. 상수 \(c\) 는 이 두 목표 사이의 균형을 조절하는 가중치입니다.
위 수식에서 핵심은 “어떤 목적함수 \(f\)를 쓰느냐“입니다. 이 논문은 softmax 출력, cross-entropy, logit 기반 마진 등 여러 후보 목적함수를 비교합니다.
목적함수
저자들은 총 7개의 후보 목적함수 \(f_1 \sim f_7\) 을 비교했고, 결론적으로 softmax나 cross-entropy보다 logit 기반 목적함수가 훨씬 안정적이라는 점을 보입니다. 가장 좋은 계열은 다음과 같은 logit-margin 형태입니다.
\[f_6(x') = \left(\max_{i \ne t} Z(x')_i - Z(x')_t\right)^+\]즉, 타깃 클래스의 logit이 다른 모든 클래스보다 커지도록 강제합니다. 이 접근은 gradient saturation 문제를 방지하고, distilled model처럼 softmax가 거의 one-hot으로 굳어 버린 경우에도 잘 작동하게 합니다.
Box constraint
입력은 유효한 이미지여야 하므로 각 픽셀 값은 다음 조건을 만족해야만 합니다. \(x+\delta \in [0,1]^n\) 저자들은 이를 보장할 세 가지 방법을 비교합니다.
| 방법 | 아이디어 | 평가 |
|---|---|---|
| Projected gradient descent | 경사하강법의 매 step 이후 픽셀값 clip | Momentum처럼 복잡한 경사하강기법에서 성능 저하 가능 |
| Clipped gradient descent | 픽셀값 대신 목적함수 내부에서 clip | flat region에 갇히기 쉬움 |
| Change of variables | \(w\)를 도입해 자동으로 범위 보장 | 가장 안정적 |
이중 가장 잘 작동한 방식은 Change of variables입니다.
\[\delta_i = \frac{1}{2}(\tanh(w_i)+1)-x_i\]이때 \(\tanh(w_i) \in [-1,1]\) 이므로, 위 치환을 사용하면 모든 \(w\)에 대해 \(x+\delta \in [0,1]^n\) 조건이 보장됩니다. 목적함수의 최적화는 주로 Adam 으로 수행하고, 상수 \(c\)는 binary search로 탐색합니다.
이산화(Discretization)
논문은 적대적 예제를 실제 이미지로 변환(저장)할 때 발생하는 오차를 보정하기 위해 반올림을 사용합니다. 실제 픽셀은 연속적인 실수값이 아니라 0~255 정수이므로, 논문은 실수 범위에서의 최적화 결과를 정수 단위로 반올림합니다. 반올림 이후 공격이 실패하면, 다시 성공할 때까지 greedy search로 픽셀값을 미세하게 조정합니다. 저자들은 이후 살펴볼 자신들의 C&W 공격이 매우 작은 섭동을 찾기 때문에, 이런 이산화 보정까지 포함해서 평가해야 공정하다고 강조합니다.
C&W 세 가지 공격
본 논문은 최적화 문제의 거리 척도로써 \(L_2\), \(L_0\), \(L_{\infty}\) 를 각각 채택하여, 각 제약 조건에 특화된 세 가지 C&W 공격을 제시합니다. 이 공격들은 “타깃 분류를 강하게 유도하는 목적함수”와 “왜곡을 최소화하는 최적화”를 결합하는 원리를 공유합니다.
1. C&W \(L_2\) Attack
가장 잘 알려진 형태의 C&W 공격입니다. Logit margin 목적함수와 change-of-variable를 결합해, 원본 이미지와 적대적 예제 사이의 \(L_2\) 거리(유클리드 거리) 는 작게 유지하며, 동시에 target class로 분류되도록 gradient descent로 최적화합니다.
\[\min_w \left\| \frac{1}{2}(\tanh(w)+1)-x \right\|_2^2 + c \cdot f\!\left(\frac{1}{2}(\tanh(w)+1)\right).\] \[f(x') = \max\left(\max_{i \ne t} Z(x')_i - Z(x')_t,\; -\kappa\right).\]\(\kappa\)는 공격 confidence 를 조절하는 파라미터입니다. \(\kappa\)가 클수록 target class에 대해 더 높은 confidence를 가지는 적대적 예제를 생성하게 됩니다. Local minimum 문제를 줄이기 위해서는 여러 초기점에서 gradient descent를 반복하는 multi-start 전략도 활용됩니다.
2. C&W \(L_0\) Attack
\(L_0\) 항은 미분 불가능하므로 일반적인 경사하강법으로 최적화하기 어렵습니다. 대신에 “변경해도 별 영향이 없는 픽셀”을 점차 고정해 나가는 반복 방식을 제안합니다.
- 처음에는 모든 픽셀 변경을 허용합니다.
- 현재 허용된 픽셀 집합 위에서 C&W \(L_2\) 공격을 실행합니다.
- gradient와 perturbation을 이용해 기여도가 가장 작은 픽셀을 찾습니다.
- 그 픽셀을 앞으로는 바꾸지 못하게 고정합니다.
- 더 이상 적대적 예제가 만들어지지 않을 때까지 반복합니다.
즉, JSMA처럼 “중요한 픽셀을 늘려 가는 방식”이 아니라, 불필요한 픽셀을 제거(고정)해 가는 방식입니다. 이 전략은 ImageNet에서도 targeted \(L_0\) 공격을 가능하게 했고, 당시 기준으로는 매우 강한 결과였습니다.
3. C&W \(L_{\infty}\) Attack
\(L_{\infty}\) 항은 공격 이후 변화량이 가장 큰 픽셀만 페널티를 주기 때문에, 단순 gradient descent는 해당 픽셀들 사이를 오가며 진동하기 쉽습니다. 저자들은 이를 피하기 위해 반복적으로 threshold \(\tau\) 를 줄여 가는 penalty 기반 방법을 사용합니다.
\[\min_{\delta} \; c \cdot f(x+\delta) + \sum_i \left[(\delta_i-\tau)^+\right]\]처음에는 큰 허용치로 시작한 뒤, 모든 좌표가 \(\tau\) 이하로 내려가면 \(\tau\) 를 0.9배로 줄여 계속 압박합니다. 결국 모든 좌표의 최대 변화를 작게 만들면서도 target class를 유지하도록 유도합니다.
실험 설정
데이터셋과 공격 대상 모델
- MNIST: Papernot et al.의 Defensive distillation 논문과 동일한 구조 사용 (accuracy 99.5%)
- CIFAR-10: 동일 구조 재현 (accuracy 80%)
- ImageNet: pre-trained Inception v3 사용 (top-5 accuracy 96%)
평가 기준
| 평가 기준 | 의미 |
|---|---|
| Best case | 가능한 타깃 클래스 중 가장 공격하기 쉬운 클래스 기준 |
| Average case | 정답이 아닌 클래스를 균등 랜덤으로 선택 |
| Worst case | 가능한 타깃 클래스 중 가장 공격하기 어려운 클래스 기준 |
ImageNet은 클래스가 1,000개이므로 계산 비용 때문에 best/worst case를 정확히 모두 계산하지 않고, 랜덤 타깃 100개로 근사합니다.
평가 방식
- targeted attack 기준으로 best / average / worst case 측정
- 평균 왜곡 크기(mean)와 공격 성공률(prob) 확인
- distilled / undistilled 모델을 모두 비교
공격 성능 평가
MNIST / CIFAR-10 결과
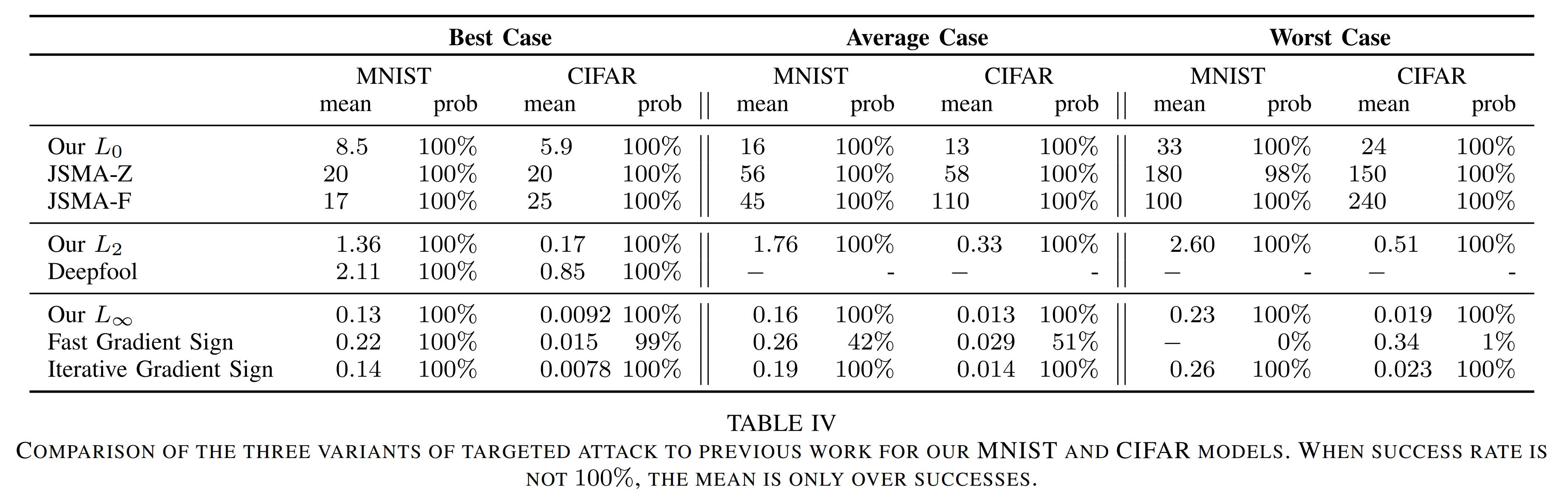
위 표의 Average case를 보면, 제안 공격은 모든 거리 척도에서 기존 공격보다 100% 성공률을 달성합니다. 심지어 \(L_0\) 와 \(L_2\) 에서 C&W 공격은 기존 방식들보다 2배에서 10배 가까이 낮은 왜곡을 필요로 합니다.
ImageNet 결과
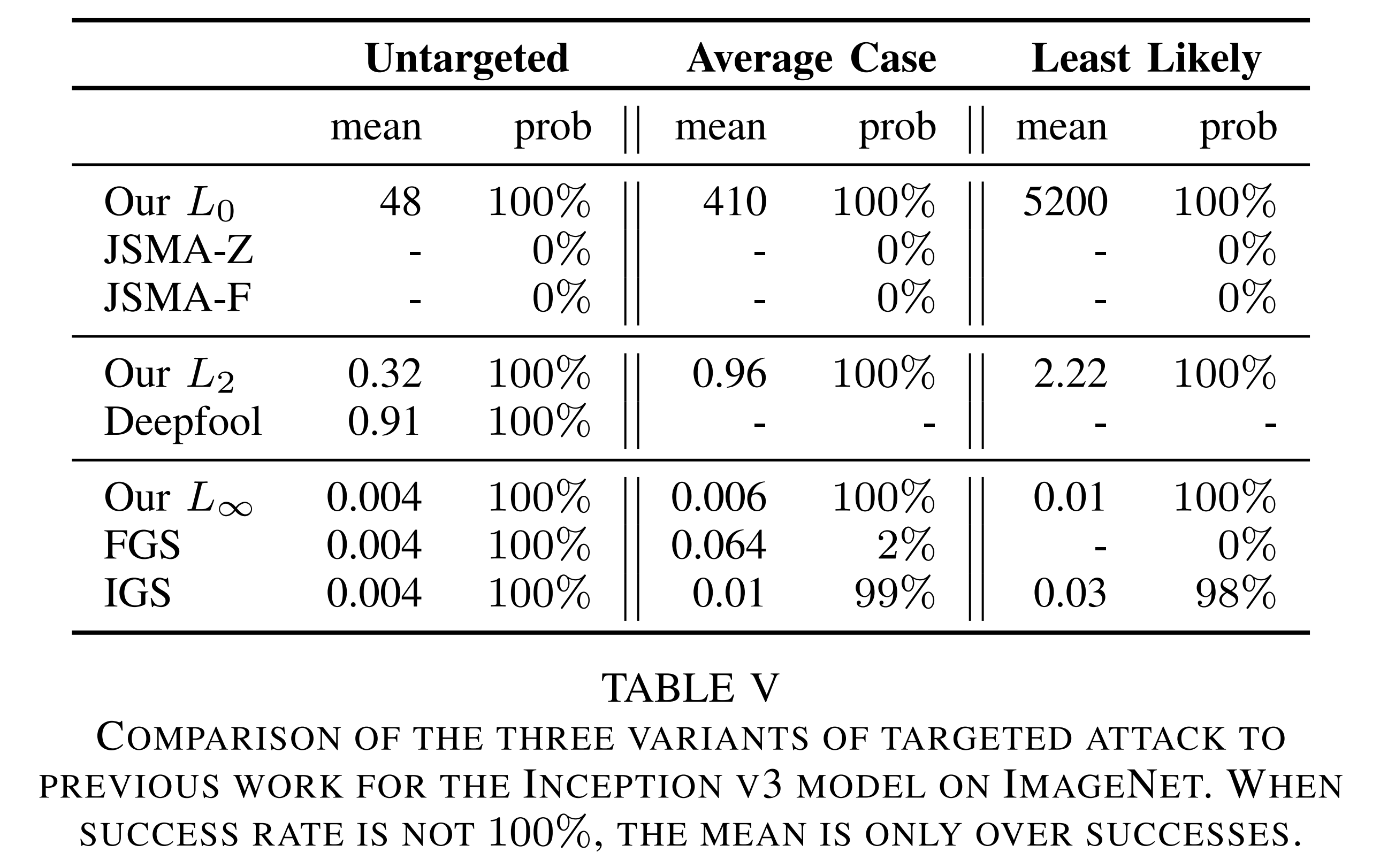
위 표에서 특히 \(L_{\infty}=0.004\) 는 대략 각 픽셀의 최하위 비트만 뒤집는 수준이라, 사실상 사람 눈으로 식별하기 어렵습니다. 논문은 이 결과를 통해 ImageNet 규모의 대형 모델에서도 공격이 전혀 사라지지 않는다는 점을 보여 줍니다. 또한 이 논문은 ImageNet에서 targeted \(L_0\) 공격을 100% 성공시킨 최초의 공개 결과라고 주장합니다.
Defensive distillation 평가
기존 방식들의 Distilled model 공격 실패 원인
논문의 핵심 통찰은 간단합니다. Defensive distillation이 정말 강건성을 높인 것이 아니라, 기존 공격이 softmax saturation과 gradient vanishing에 취약했기 때문입니다. 높은 temperature \(T\) 로 학습한 뒤 테스트 때 temperature를 1로 내리면, logits의 절댓값이 매우 커집니다. 논문에서의 측정에 따르면, distillation 없이 학습한 모델의 \(\|Z(x)\|_1\) 평균은 5.8 정도였지만, \(T=100\) distilled model에서는 평균이 482 수준까지 커졌습니다. 그 결과 softmax 출력은 사실상 one-hot이 되고, 32-bit float에서 gradient가 0으로 떨어져 버립니다. 그러면 cross-entropy나 softmax 출력에 직접 의존하는 기존 공격은 “방어에 막혔다”고 착각한 채 실패합니다. 즉, distillation은 decision boundary를 안전하게 만든 것이 아니라, 기존 공격의 수치적 약점을 찌른 것에 가깝습니다.
C&W 공격의 Distilled model 공격 결과
저자들은 같은 설정으로 Defensive distillation을 다시 구현해 실험합니다. 결과는 아래와 같습니다.
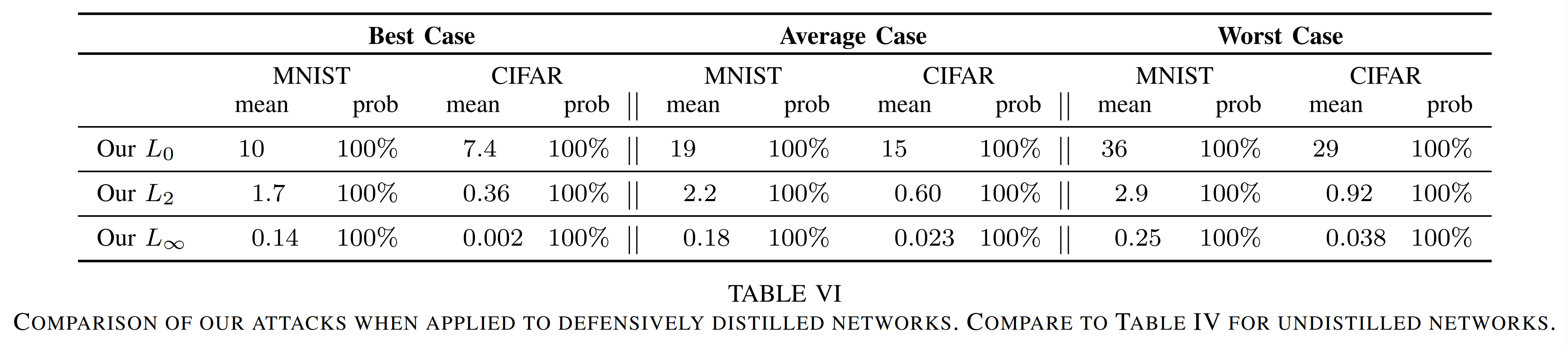
Undistilled 모델과 비교하면 평균 왜곡 크기가 약간 증가한 경우는 있지만, 공격 성공률은 여전히 100% 입니다. 즉, Defensive distillation은 기존 주장과 달리 거의 실질적인 방어력을 제공하지 못했습니다.
Temperature 효과
기존 논문은 temperature를 높일수록 공격 성공률이 급감한다고 보고했습니다. 그러나 C&W \(L_2\) 공격으로 다시 평가하면, temperature와 adversarial distance 사이에는 유의미한 상관이 거의 없습니다. 본 논문은 MNIST에서 상관계수 \(\rho = -0.05\) 를 보고하며, 이는 temperature 증가가 robustness 향상이 아니라 기존 공격 실패율 증가만 가져옴을 밝힙니다.
High-confidence transferability
저자들은 방어를 평가할 때 Direct White-box attack만 볼 것이 아니라, 전이성(transferability) 도 함께 봐야 한다고 주장합니다.
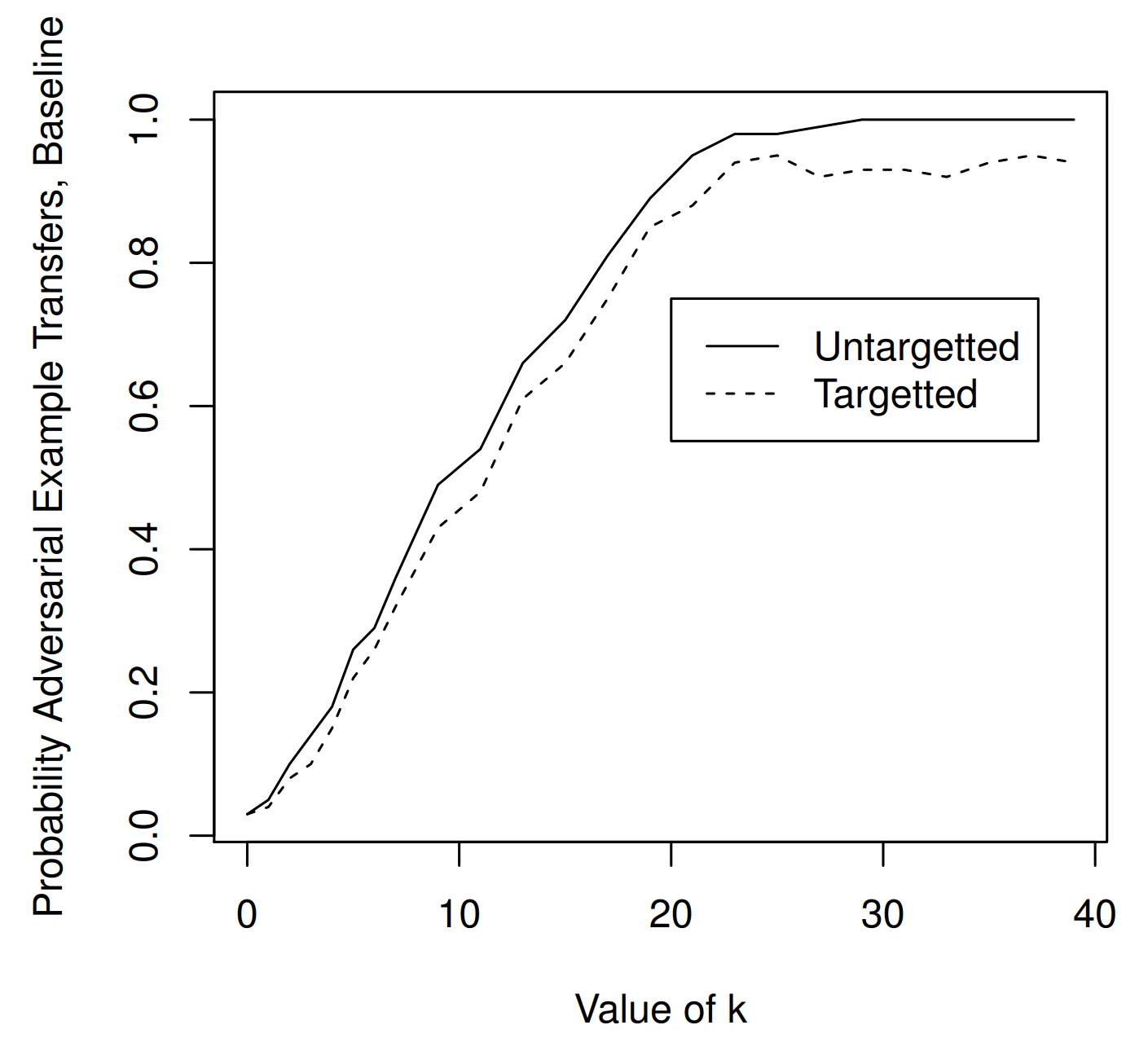
위 표는 일반 모델 간 실험 결과입니다. 동일한 구조를 가진 두 개의 일반(undistilled) 모델을 사용하되, 각 모델을 훈련 데이터의 절반씩으로 따로 학습시켜 source model과 target model을 분리합니다. 공격자는 source model에서 적대적 예제를 생성하고, 이를 target model에 입력해 transfer 성공률을 측정합니다.
그 결과, 일반 모델 사이 전이는 \(\kappa \approx 20\) 부근에서 거의 100%를 달성합니다.
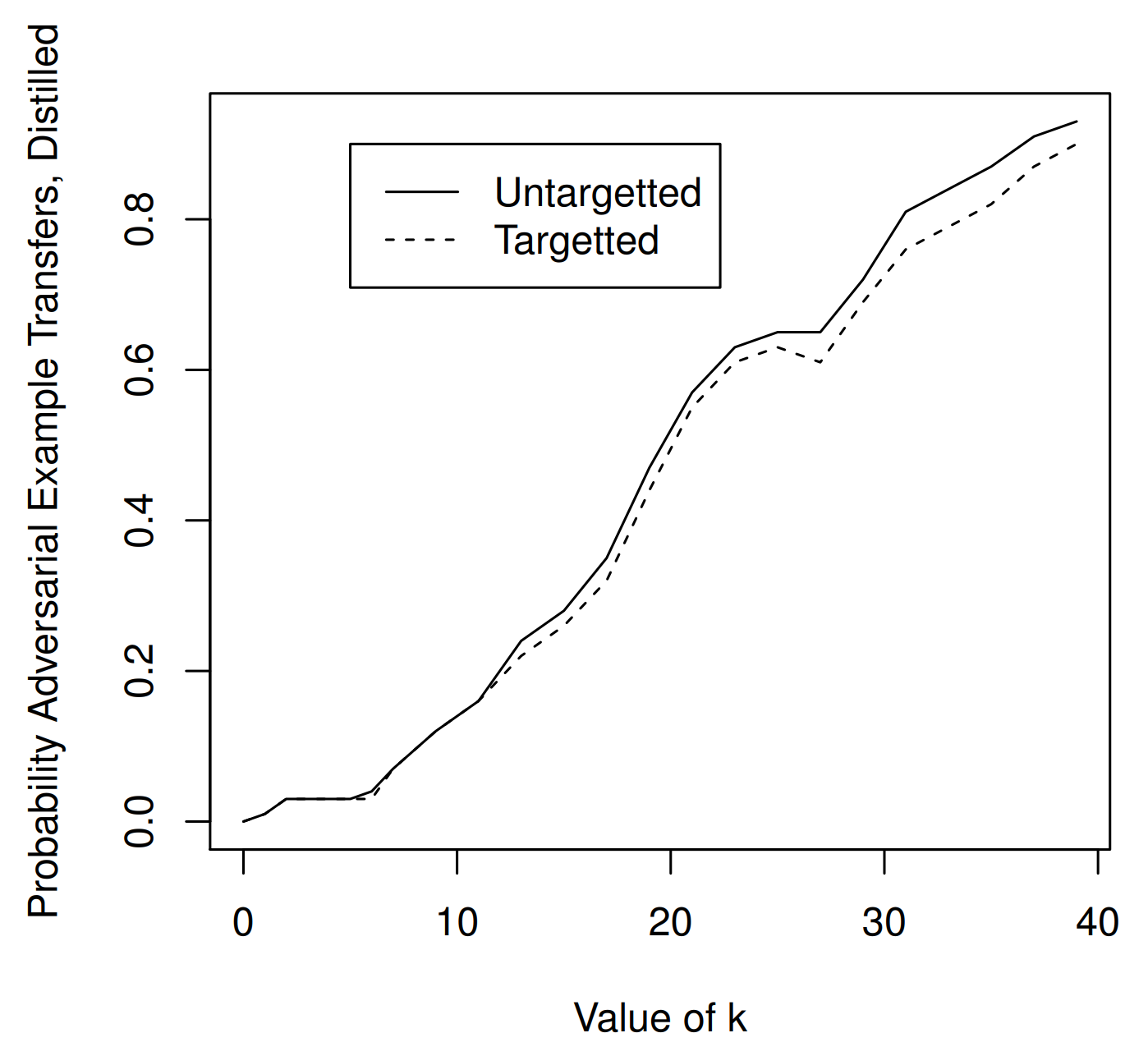
위 표는 일반 모델과 distilled 모델 간 실험 결과입니다. target model만 temperature \(T=100\) 으로 defensive distillation을 적용한 모델로 바꾸어, 일반 모델에서 만든 적대적 예제가 distilled model에도 전달되는지를 평가합니다.
그 결과, 일반 모델에서 만든 적대적 예제를 distilled 모델로 전이할 때도 결국 성공하는 모습을 보여줍니다. 또한 distilled model 전이에서 100%에 가까워지려면 더 큰 \(\kappa \approx 40\)를 필요로 합니다.
결론
본 논문은 Defensive distillation이 adversarial robustness를 실질적으로 높였다는 당시의 주장을 반박하고, 그 대신 더 강한 공격과 더 엄밀한 평가 프로토콜이 필요하다는 기준을 제시한 고전 논문입니다.
핵심 결론은 다음과 같습니다.
- 방어 기법은 약한 공격 기법을 막았다는 이유만으로 안전하다고 볼 수 없기 때문에 강한 공격이 곧 평가 기준이 되어야 한다.
- \(L_0\), \(L_2\), \(L_{\infty}\) 각각에 대해 기존보다 더 강한 공격을 만들 수 있다.
- Defensive distillation은 기존 공격을 실패하게 만들 뿐, C&W 공격에는 거의 방어력이 없다.
- robust defense를 주장하려면 직접 white-box 공격뿐 아니라 transferability까지 함께 막아야 한다.
즉, 이 논문은 “새 방어를 제안하는 것”보다 더 근본적으로, 강건성을 어떻게 평가해야 하는가라는 질문의 기준점을 바꿔 놓았습니다.