Paper: Towards Evaluating the Robustness of Neural Networks
Authors: Nicholas Carlini, David Wagner
Venue: 2017 IEEE Symposium on Security and Privacy (SP)
Introduction
Deep learning classifiers achieve high accuracy, but adding even very small perturbations to inputs can induce desired misclassifications. Such adversarial examples make it difficult to deploy models in security-sensitive domains such as autonomous driving, malware detection, and speech recognition.
This paper directly examines Defensive distillation, which had attracted attention as a strong defense at the time. According to prior reports, distillation was known to reduce the success rate of existing attacks from 95% to 0.5%. However, the authors argue that this may not be because “the model truly became robust,” but rather because the existing attack algorithms were too weak and therefore failed.
To verify this claim, the authors propose three new attacks corresponding to the \(L_0\), \(L_2\), and \(L_{\infty}\) distance constraints, respectively. They show that these attacks can find adversarial examples with 100% success rate not only on standard models but also on defensively distilled models.
The core message of this paper is simple. Just because a defense blocks existing attacks does not mean robustness is guaranteed. A model can only be called robust when it withstands stronger attacks, more stable objective functions, and transferability-based evaluations together.
Preliminaries
Threat Model
The paper fundamentally assumes a white-box attack. That is, the attacker has full access to the model architecture, parameters, and gradients. The authors regard this as a conservative yet realistic assumption, because even in a black-box setting, attackers can train a substitute model and then transfer the attack.
Notation
| Symbol | Meaning |
|---|---|
| \(F(x)\) | Full classifier output including softmax |
| \(Z(x)\) | Logit output just before softmax |
| \(C(x)\) | Class predicted by the model |
| \(C^*(x)\) | Ground-truth class of input \(x\) |
| \(x\) | Original input |
| \(x' = x + \delta\) | Adversarial example |
| \(t\) | Target class chosen by the attacker |
| \(D(x, x')\) | Distance between original and adversarial example |
Targeted Attacks
This paper evaluates attacks based on targeted attacks, which are stronger than untargeted attacks. In this setting, the adversarial attack does not merely induce misclassification but forces the model to classify the input into a class \(t\) specified by the attacker.
Distance Metrics
Following prior work, the paper uses three \(L_p\) metrics.
| Distance | Meaning |
|---|---|
| \(L_0\) | Total number of modified pixels |
| \(L_2\) | Euclidean distance between the original and modified images |
| \(L_{\infty}\) | Maximum pixel-wise change after modification |
The authors do not commit to which distance metric best aligns with human perception. The above three were the most widely used in the literature at the time, and since the distillation paper also claimed safety using these metrics, they are adopted here for an apples-to-apples comparison.
Defensive Distillation
Defensive distillation repurposes distillation, originally designed for model compression, as a defense mechanism.
- Train a teacher network with an arbitrary constant temperature \(T\).
The softmax with temperature is given below; as \(T\) increases, the probability differences between classes shrink, making the softmax output more uniform.
\[\operatorname{softmax}(x, T)_i = \frac{e^{x_i/T}}{\sum_j e^{x_j/T}}\]- Generate soft labels for the entire training dataset using the trained teacher network.
- Train a student network with the same architecture as the teacher network, using these soft labels as ground-truth targets.
- At test time, restore the temperature to 1 and use the student network as a regular classifier.
Prior work argued that high \(T\) smooths the decision boundary and thus makes the model less vulnerable to adversarial examples. However, this paper shows that this interpretation is incorrect. At the time, the safety claims of Defensive distillation were primarily based on the result that “existing attacks did not work well on distilled models.” Therefore, to properly evaluate this defense, we must first examine what the standard attacks of the time were and whether those attacks truly provide a reliable upper bound on the model’s robustness.
Prior Attack Methods
Motivated by this concern, the paper organizes existing attacks and shows why they alone are insufficient to evaluate model robustness.
| Attack Method | Optimization Target | Characteristics |
|---|---|---|
| L-BFGS | \(L_2\) | Representative optimization-based attack from early adversarial example research |
| Fast Gradient Sign (FGS/FGSM) | \(L_{\infty}\) | Simultaneously perturbs all pixels in one step to generate adversarial examples very quickly |
| Iterative Gradient Sign | \(L_{\infty}\) | Iterative version of FGSM. Modifies the image multiple times by small amounts to enable finer attacks |
| JSMA | \(L_0\) | Selects and modifies only a few highly influential pixels based on the Jacobian saliency map |
| DeepFool | Mostly \(L_2\) | Untargeted. Modifies samples based on the distance to the nearest decision boundary that changes the classification result |
From this paper’s perspective, the issues with prior attacks are as follows.
-
Some attacks are designed to generate adversarial examples quickly, but they do not produce minimal adversarial perturbations and therefore lack optimality.
-
Some attacks are sensitive to the stability of the objective function or gradients. Because Defensive distillation-trained models exhibit gradient vanishing at test time, gradient information is lost. As a result, the attack algorithm falls into numerical instability and fails to navigate the optimization landscape.
It is precisely at this point that the authors highlight the limitations of existing evaluation methodologies. Robustness evaluation ultimately comes down to how strong an attack one can mount to upper-bound the model’s vulnerability; if the attack itself is unstable, the conclusion that “the defense is safe” cannot be trusted. Therefore, the paper argues for redesigning the attack algorithm itself to be stronger and more stable.
Proposed Method
Basic Optimization Perspective
The authors formulate adversarial example generation as the following constrained optimization problem.
\[\min_{\delta} D(x, x+\delta) \quad \text{s.t.} \quad C(x+\delta)=t,\; x+\delta \in [0,1]^n\]However, since the model’s classification result is a discrete and discontinuous label, the classification constraint \(C(x+\delta)=t\) is difficult to handle directly. Therefore, the classification constraint is folded into the objective function as follows.
\[\min_{\delta} \|\delta\|_p + c \cdot f(x+\delta) \quad \text{s.t.} \quad x+\delta \in [0,1]^n\]Here, the added term \(f(x+\delta)\) is a continuous, optimizable penalty term that replaces the original classification constraint. That is, \(f\) is designed so that it becomes small or non-positive when \(x+\delta\) is classified as the target class \(t\), allowing the optimization process to simultaneously push toward “keeping the image close to the original” and “misclassifying it into the target class.” The constant \(c\) is a weight that balances these two objectives.
The key question in the above formulation is “which objective function \(f\) to use.” This paper compares various candidate objective functions, including those based on softmax outputs, cross-entropy, and logit margins.
Objective Functions
The authors compared seven candidate objective functions \(f_1 \sim f_7\) in total, and concluded that logit-based objective functions are far more stable than softmax or cross-entropy. The best family takes the following logit-margin form.
\[f_6(x') = \left(\max_{i \ne t} Z(x')_i - Z(x')_t\right)^+\]That is, it forces the target class logit to exceed all other class logits. This approach prevents gradient saturation and works well even on distilled models where the softmax has essentially frozen into a one-hot vector.
Box Constraint
Since the input must be a valid image, every pixel value must satisfy \(x+\delta \in [0,1]^n\). The authors compare three approaches to enforce this.
| Method | Idea | Evaluation |
|---|---|---|
| Projected gradient descent | Clip pixel values after each gradient descent step | Performance can degrade with sophisticated optimizers like momentum |
| Clipped gradient descent | Clip inside the objective function instead of clipping the pixel values | Easily trapped in flat regions |
| Change of variables | Introduce \(w\) to automatically guarantee the range | Most stable |
Among these, the most effective approach is change of variables.
\[\delta_i = \frac{1}{2}(\tanh(w_i)+1)-x_i\]Since \(\tanh(w_i) \in [-1,1]\), this substitution guarantees \(x+\delta \in [0,1]^n\) for all \(w\). Optimization of the objective function is mainly performed with Adam, and the constant \(c\) is found by binary search.
Discretization
The paper applies rounding to compensate for errors that arise when converting (saving) adversarial examples to real images. Since actual pixels are not continuous real numbers but integers between 0 and 255, the paper rounds the optimization result from the real-valued domain to integer values. If the attack fails after rounding, a greedy search adjusts pixel values until the attack succeeds again. The authors emphasize that since the C&W attacks examined later find very small perturbations, they must be evaluated together with this discretization correction to ensure fairness.
Three C&W Attacks
This paper adopts \(L_2\), \(L_0\), and \(L_{\infty}\) as the distance metrics in the optimization problem, presenting three C&W attacks specialized for each constraint. These attacks share the principle of combining “an objective function that strongly induces the target classification” with “an optimization that minimizes the distortion.”
1. C&W \(L_2\) Attack
This is the best-known form of the C&W attack. By combining the logit-margin objective with change-of-variables, it keeps the \(L_2\) distance (Euclidean distance) between the original image and the adversarial example small while simultaneously optimizing via gradient descent so that the example is classified into the target class.
\[\min_w \left\| \frac{1}{2}(\tanh(w)+1)-x \right\|_2^2 + c \cdot f\!\left(\frac{1}{2}(\tanh(w)+1)\right).\] \[f(x') = \max\left(\max_{i \ne t} Z(x')_i - Z(x')_t,\; -\kappa\right).\]\(\kappa\) is a parameter that controls the attack confidence. A larger \(\kappa\) produces adversarial examples with higher confidence in the target class. To mitigate local minima issues, a multi-start strategy that repeats gradient descent from multiple initial points is also used.
2. C&W \(L_0\) Attack
Since the \(L_0\) term is non-differentiable, it is hard to optimize via standard gradient descent. Instead, the authors propose an iterative scheme that progressively fixes “pixels whose modification has little effect.”
- Initially allow all pixels to change.
- Run the C&W \(L_2\) attack on the currently allowed pixel set.
- Use the gradient and perturbation to identify the pixel with the smallest contribution.
- Fix that pixel so it can no longer be changed.
- Repeat until adversarial examples can no longer be produced.
That is, unlike JSMA which “adds important pixels,” this approach removes (fixes) unnecessary pixels. This strategy enabled targeted \(L_0\) attacks even on ImageNet, which was a remarkable result by the standards of the time.
3. C&W \(L_{\infty}\) Attack
Since the \(L_{\infty}\) term penalizes only the pixels with the largest changes, plain gradient descent tends to oscillate among those pixels. To avoid this, the authors use a penalty-based approach that iteratively decreases a threshold \(\tau\).
\[\min_{\delta} \; c \cdot f(x+\delta) + \sum_i \left[(\delta_i-\tau)^+\right]\]Starting with a large allowance, once all coordinates fall below \(\tau\), the threshold is reduced by a factor of 0.9 to apply continued pressure. Eventually, this drives the maximum change across all coordinates to be small while maintaining the target class.
Experimental Setup
Datasets and Target Models
- MNIST: same architecture as the Defensive distillation paper by Papernot et al. (accuracy 99.5%)
- CIFAR-10: same architecture reproduced (accuracy 80%)
- ImageNet: pre-trained Inception v3 (top-5 accuracy 96%)
Evaluation Criteria
| Criterion | Meaning |
|---|---|
| Best case | Easiest target class to attack among possible target classes |
| Average case | Uniformly random selection among non-ground-truth classes |
| Worst case | Hardest target class to attack among possible target classes |
Since ImageNet has 1,000 classes, the best/worst cases are not computed exhaustively due to computational cost; instead, they are approximated using 100 random targets.
Evaluation Methodology
- Measure best / average / worst case under targeted attacks
- Report mean distortion (mean) and attack success rate (prob)
- Compare both distilled and undistilled models
Attack Performance
MNIST / CIFAR-10 Results
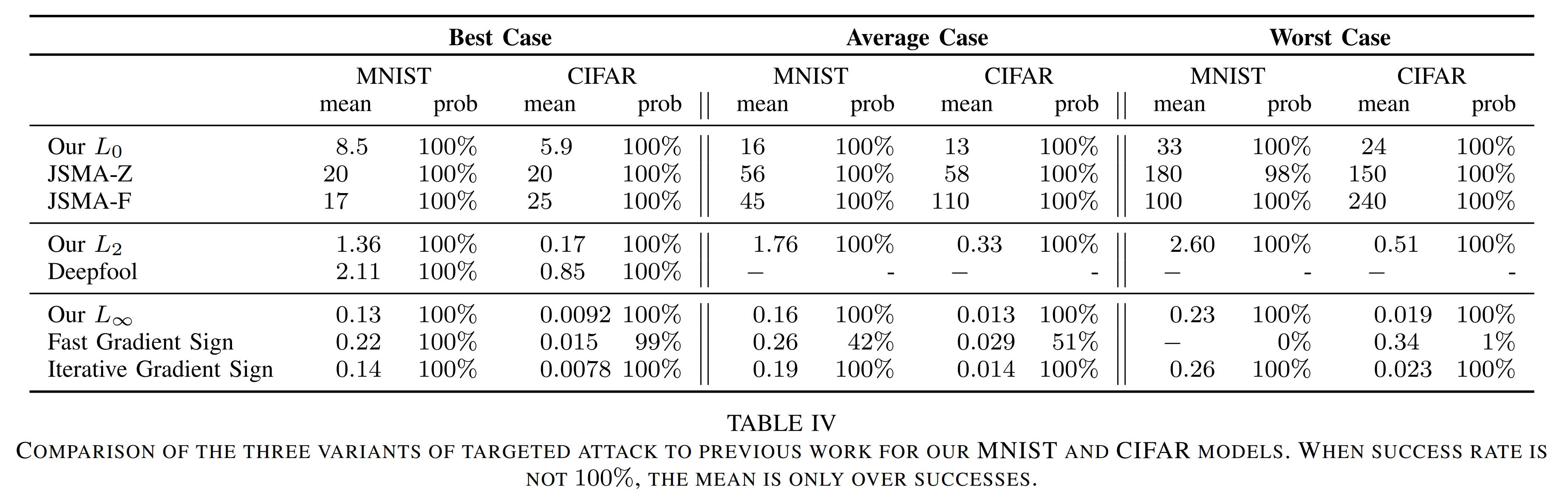
Looking at the Average case in the table above, the proposed attack achieves a 100% success rate under all distance metrics, surpassing all prior attacks. Moreover, on \(L_0\) and \(L_2\), the C&W attack requires distortions that are 2x to nearly 10x smaller than those of prior methods.
ImageNet Results
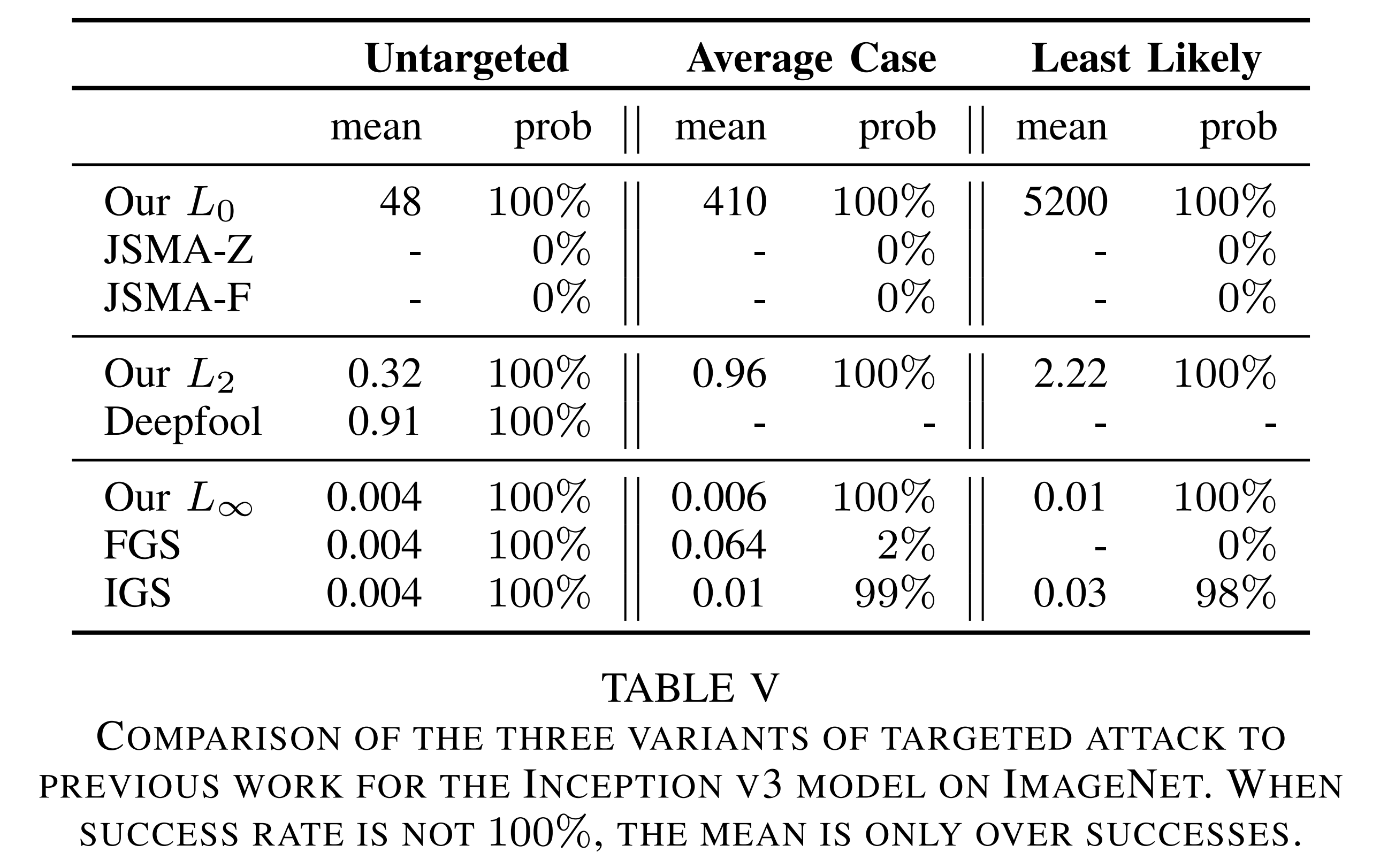
In the table above, in particular, \(L_{\infty}=0.004\) corresponds to roughly flipping only the least-significant bit of each pixel, making the perturbation virtually imperceptible to humans. The paper shows through this result that attacks do not disappear even on ImageNet-scale large models. The paper also claims to be the first publicly reported result of achieving a 100% targeted \(L_0\) attack on ImageNet.
Evaluating Defensive Distillation
Why Prior Methods Failed to Attack Distilled Models
The paper’s central insight is simple. Defensive distillation did not truly improve robustness; rather, existing attacks were vulnerable to softmax saturation and gradient vanishing. After training with high temperature \(T\) and lowering the temperature to 1 at test time, the absolute values of the logits become very large. According to the paper’s measurements, the average \(\|Z(x)\|_1\) for a model trained without distillation was around 5.8, but on a \(T=100\) distilled model the average grew to about 482. As a result, the softmax output essentially becomes one-hot, and in 32-bit float, the gradient drops to zero. Existing attacks that directly rely on cross-entropy or softmax outputs then fail, mistakenly believing they were “blocked by the defense.” In other words, distillation did not make the decision boundary safer; rather, it exploited the numerical weaknesses of existing attacks almost by accident.
C&W Attack Results on Distilled Models
The authors re-implement Defensive distillation under the same settings and run experiments. The results are as follows.
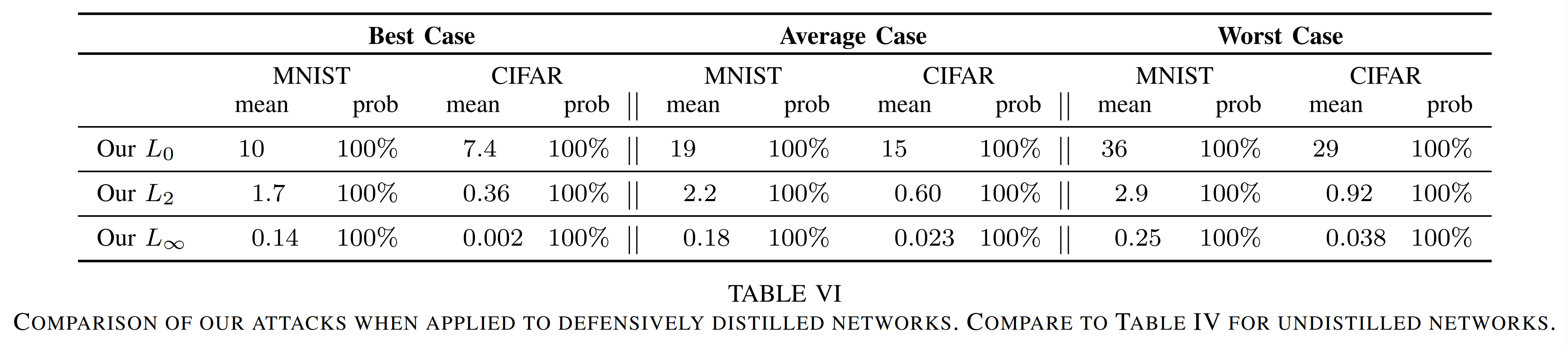
Compared to the undistilled model, the average distortion increases slightly in some cases, but the attack success rate remains 100%. That is, contrary to prior claims, Defensive distillation provides almost no actual defensive capability.
Temperature Effect
Prior work reported that the attack success rate plummets as the temperature increases. However, when re-evaluated with the C&W \(L_2\) attack, there is almost no meaningful correlation between temperature and adversarial distance. The paper reports a correlation coefficient of \(\rho = -0.05\) on MNIST, demonstrating that increasing the temperature does not improve robustness but only increases the failure rate of existing attacks.
High-Confidence Transferability
The authors argue that when evaluating defenses, one must consider not only direct white-box attacks but also transferability.
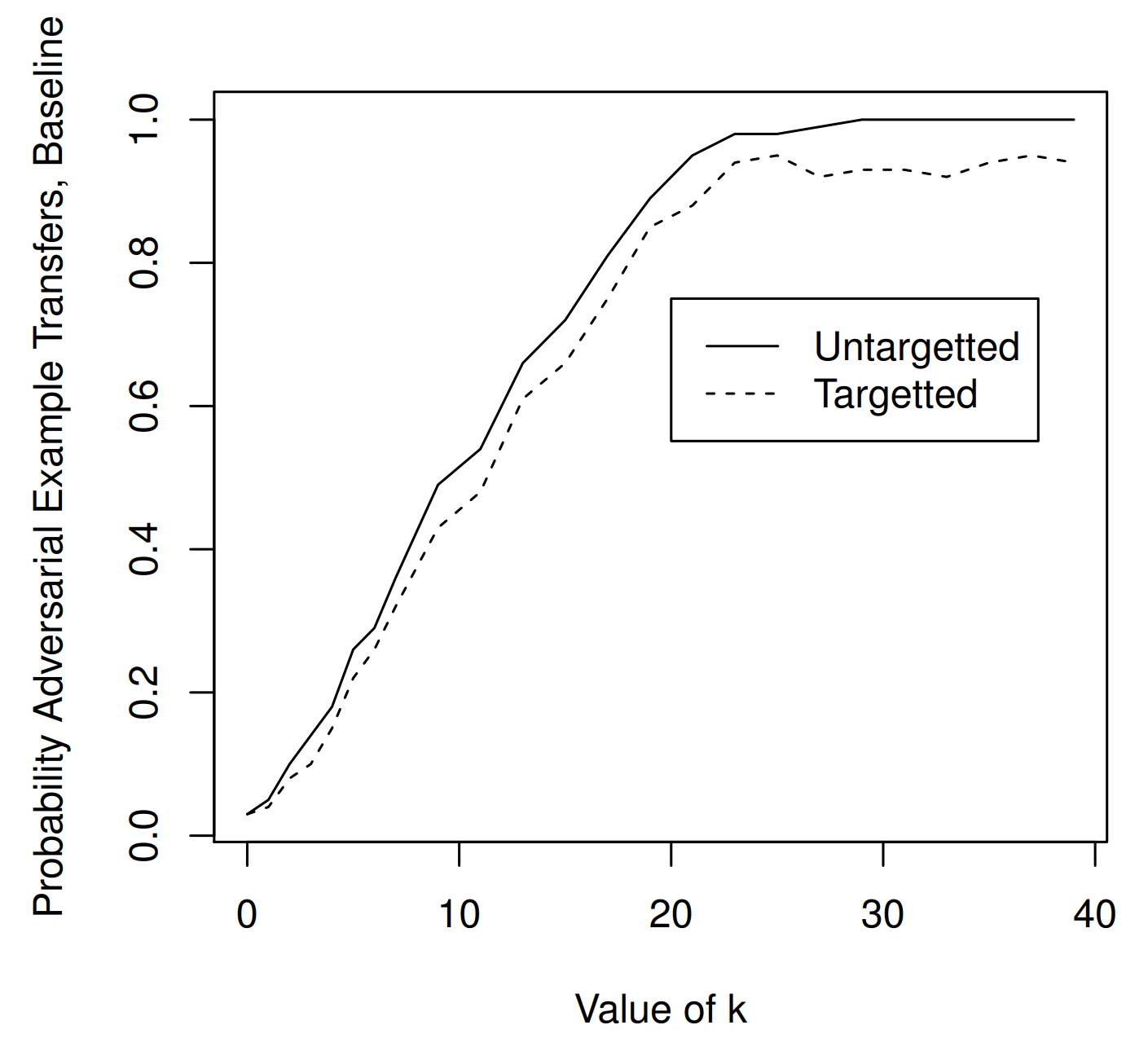
The figure above shows the experimental results between standard models. Two standard (undistilled) models with the same architecture are used, but each model is trained separately on half of the training data, separating the source model from the target model. The attacker generates adversarial examples on the source model and feeds them to the target model to measure the transfer success rate.
As a result, transfer between standard models reaches nearly 100% around \(\kappa \approx 20\).
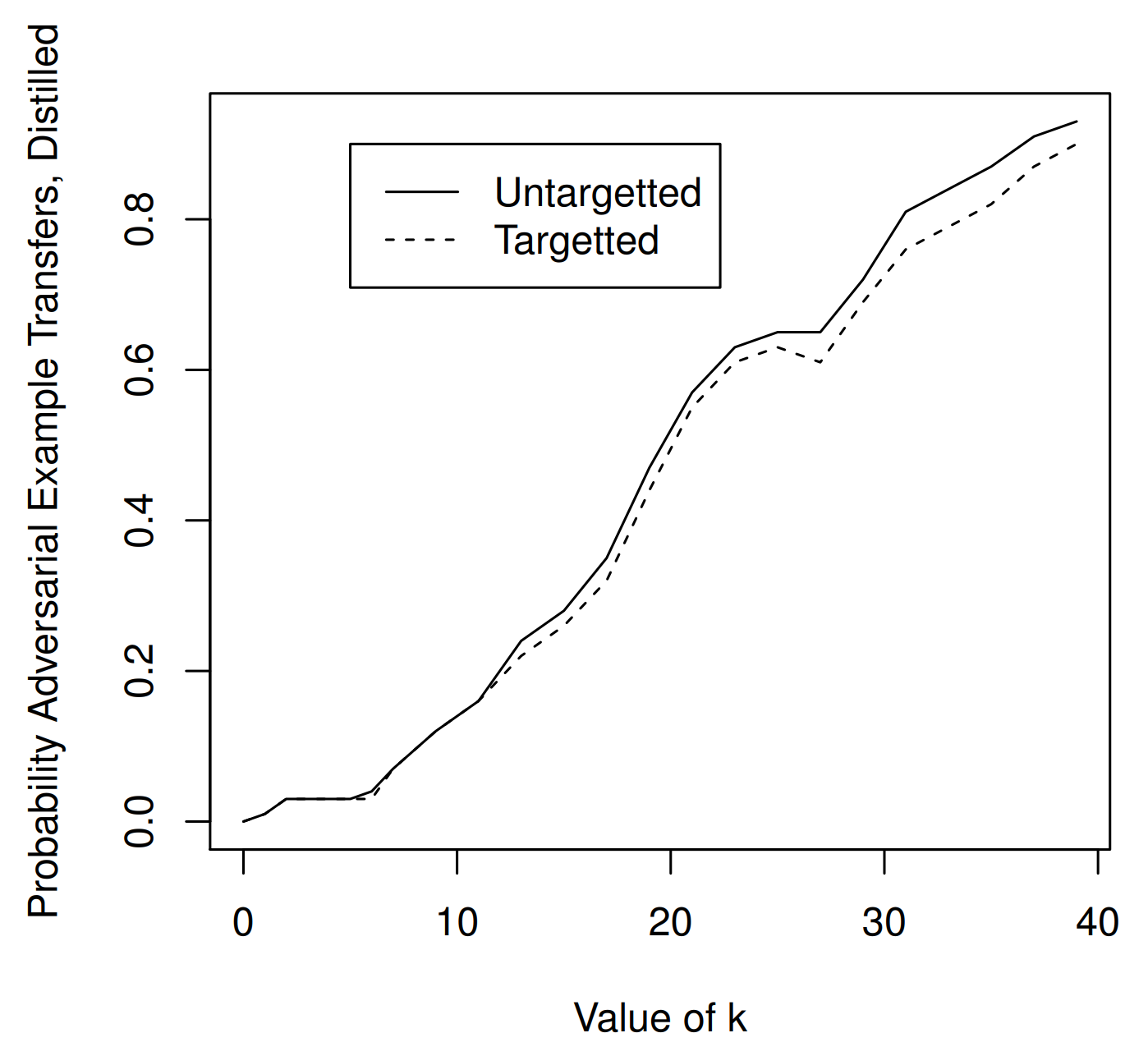
The figure above shows the experimental results between a standard model and a distilled model. Only the target model is replaced with a model trained with defensive distillation at temperature \(T=100\), to evaluate whether adversarial examples crafted on a standard model also transfer to a distilled model.
The result shows that adversarial examples crafted on a standard model do eventually succeed when transferred to the distilled model. However, achieving close to 100% transfer to the distilled model requires a larger \(\kappa \approx 40\).
Conclusion
This paper is a classic that refutes the prevailing claim at the time that Defensive distillation substantially improved adversarial robustness, and instead establishes the principle that stronger attacks and more rigorous evaluation protocols are required.
The key conclusions are as follows.
- A defense cannot be considered safe simply because it blocks weak attacks; strong attacks must be the standard for evaluation.
- For each of \(L_0\), \(L_2\), and \(L_{\infty}\), attacks stronger than prior work can be constructed.
- Defensive distillation merely causes existing attacks to fail; it provides almost no defense against C&W attacks.
- To claim a robust defense, one must defend not only against direct white-box attacks but also against transferability.
In other words, more fundamentally than “proposing a new defense,” this paper changed the reference point of the question of how robustness should be evaluated.